- Задачи на регулярные выражения JavaScript. Часть 1
- Учебник JavaScript
- Практика
- Работа с DOM
- Практика
- Некоторые продвинутые вещи
- Рекомендованное ES6
- Регулярки
- Разное
- Работа с канвасом
- Практика
- Контекст
- Drag-and-Drop
- Практика по ООП
- Практика
- Promise ES6
- Библиотека jQuery
- Задачи для решения
- На ‘.’, символы
- На экранировку
- На жадность
- Тестер и генератор регулярных выражений
- Проверить цифровые выражения
- Проверка символьных выражений
- Выражения особых потребностей
- Разминаем мозг регулярными выражениями — Regex Tuesday Challenge
- 1. Выделяем повторяющиеся слова (Ссылка ведет на задачу)
- 2. Оттенки серого
- 3. Даты найти строки сответствующем этому шаблону: YYYY/MM/DD HH:MM(:SS)
- 4. Курсив в MarkDown
- 5. Числа
- 6. IPv4 адреса
- 7. Доменные имена
- 8. Повторяющиеся пункты в списке MarkDown
- 9. Ссылки в MarkDown
- 10. Делим предложение на токены.
- 11. Буквы в алфавитном порядке.
- 12. Исправляем пробелы
- 13. Повторяющиеся слова друг под другом
- 14. Брутфорсим химические элементы
- 15. Музыкальные аккорды
- 16. Брутфорсим химические элементы
- 17. Регулярное выражение для регулярного выражения.
- 18. IRC — Сообщения
- JavaScript: изучаем регулярные выражения на практике
Задачи на регулярные выражения JavaScript. Часть 1
Учебник JavaScript
Практика
Работа с DOM
Практика
Некоторые продвинутые вещи
Рекомендованное ES6
Некоторые видео могут забегать вперед, тк к этому месту учебника мы прошли еще не весь ES6. Просто пропускайте такие видео, посмотрите потом.
Регулярки
Разное
Работа с канвасом
Практика
Контекст
Drag-and-Drop
- Урок №
Введение, задач нет - Урок №
Основы
работы с ООП - Урок №
Наследование
классов в JavaScript
Продвинутая работа
с классами на JavaScript —> - Урок №
Применение
ООП при работе с DOM - Урок №
Практика
по ООП в JavaScript - Тут скоро будут еще уроки
по функциональному и прототипному
стилю ООП.
Практика по ООП
Ваша задача: посмотрите, попробуйте повторить.
Практика
Promise ES6
Библиотека jQuery
Тк. jQuery устаревает, объявляю эти уроки не обязательными и выношу в конец учебника (так по уровню уроки середины учебника, если что). В перспективе переедет в отдельный учебник по jq.
Перед решением задач изучите теорию к данному уроку.
Задачи для решения
На ‘.’, символы
Дана строка ‘ahb acb aeb aeeb adcb axeb’. Напишите регулярку, которая найдет строки ahb, acb, aeb по шаблону: буква ‘a’, любой символ, буква ‘b’.
Дана строка ‘aba aca aea abba adca abea’. Напишите регулярку, которая найдет строки abba adca abea по шаблону: буква ‘a’, 2 любых символа, буква ‘a’.
Дана строка ‘aba aca aea abba adca abea’. Напишите регулярку, которая найдет строки abba и abea, не захватив adca.
Дана строка ‘aa aba abba abbba abca abea’. Напишите регулярку, которая найдет строки aba, abba, abbba по шаблону: буква ‘a’, буква ‘b’ любое количество раз, буква ‘a’.
Дана строка ‘aa aba abba abbba abca abea’. Напишите регулярку, которая найдет строки aa, aba, abba, abbba по шаблону: буква ‘a’, буква ‘b’ любое количество раз (в том числе ниодного раза), буква ‘a’.
Дана строка ‘aa aba abba abbba abca abea’. Напишите регулярку, которая найдет строки aa, aba по шаблону: буква ‘a’, буква ‘b’ один раз или ниодного, буква ‘a’.
Дана строка ‘aa aba abba abbba abca abea’. Напишите регулярку, которая найдет строки aa, aba, abba, abbba, не захватив abca abea.
Дана строка ‘ab abab abab abababab abea’. Напишите регулярку, которая найдет строки по шаблону: строка ‘ab’ повторяется 1 или более раз.
На экранировку
Дана строка ‘a.a aba aea’. Напишите регулярку, которая найдет строку a.a, не захватив остальные.
Дана строка ‘2+3 223 2223’. Напишите регулярку, которая найдет строку 2+3, не захватив остальные.
Дана строка ’23 2+3 2++3 2+++3 345 567′. Напишите регулярку, которая найдет строки 2+3, 2++3, 2+++3, не захватив остальные (+ может быть любое количество).
Дана строка ’23 2+3 2++3 2+++3 445 677′. Напишите регулярку, которая найдет строки 23, 2+3, 2++3, 2+++3, не захватив остальные.
Дана строка ‘*+ *q+ *qq+ *qqq+ *qqq qqq+’. Напишите регулярку, которая найдет строки *q+, *qq+, *qqq+, не захватив остальные.
На жадность
Дана строка ‘aba accca azzza wwwwa’. Напишите регулярку, которая найдет все строки по краям которых стоят буквы ‘a’, и заменит каждую из них на ‘!’. Между буквами a может быть любой символ (кроме a).
Источник
Тестер и генератор регулярных выражений
Тестер и генератор регулярных выражений поможет вам протестировать регулярное выражение и сгенерировать regex-код для JavaScript PHP Go JAVA Ruby и Python.
Проверить цифровые выражения
- Цифра:
- N цифры:
- Не менее N цифр:
- м-n цифр:
- Нулевые и ненулевые стартовые цифры:
- Ненулевое число с точностью до двух знаков после запятой:
- Положительное или отрицательное число с одним или двумя десятичными знаками:
- Положительные, отрицательные и десятичные числа:
- Положительное действительное число с двумя десятичными знаками после запятой:
- Положительное действительное число с 1 до 3 знаков после запятой:
- Ненулевое положительное целое число:
- Ненулевое отрицательное целое число:
- Неотрицательные целые числа:
- Неположительное целое число:
- Неотрицательные числа с плавающей запятой:
- Неположительное число с плавающей точкой:
- Число с плавающей точкой:
- Negative Float:
- Число с плавающей точкой:
Проверка символьных выражений
- Буквенно-цифровые символы:
- Все символы длиной 3-20:
- Строка из 26 букв:
- Строка из 26 заглавных букв английского алфавита:
- Строка из 26 строчных буквенных символов:
- Строка из цифр и 26 букв:
- Строка из цифр, 26 букв или подчеркивания:
- ввод с ^%&’,;=?$\»:
- Запрещается вводить символы с
Выражения особых потребностей
- Электронная почта:
- URL или доменное имя:
- Дата (MM/DD/YYYY)/(MM-DD-YYYY)/(MM.DD.YYYY)/(MM DD YYYY):
- 12 месяцев в году(01
12):
31 день в месяц(01
31):
Источник
Разминаем мозг регулярными выражениями — Regex Tuesday Challenge
Я хочу предложить вам поломать голову вечерок-другой над интересными задачками, на регулярные выражения, которые Callum Macrae выкладывает на своем сайте на GitHub каждый Вторник.
Каждый вопрос представлен в виде набора тестов. Задача — написать такой регулярное выражение, чтобы все тесты стали зелеными.
Некоторые из задач сами по себе довольно простые, а самая интересная часть — в том, чтобы написать наиболее короткое возможное регулярное выражение.
Тесты используют JavaScript Regex движок вашего браузера, который обладает всеми основными возможностями PCRE. Подробнее можно посмотреть тут (англ.) , в колонке ECMA в таблице.
Я собрал в этой статье русские версии задач и материалов, которые могут помочь в их решении. Было бы интересно увидеть самые интересные решения в комментах.
UPD: В регулярных выражениях ECMAScript нету ретроспективных проверок.
1. Выделяем повторяющиеся слова (Ссылка ведет на задачу)
Задача:
Выделить тегом повторяющиеся слова.
Примеры:
Тhis is is a test => this is is a test
2. Оттенки серого
Задача:
Выбрать отенки серого в разных цветовых системах.
Почитать про цвета можно по этой ссылке.
Примеры:
3. Даты найти строки сответствующем этому шаблону: YYYY/MM/DD HH:MM(:SS)
Задача:
Выбрать существующие даты между 1000 и 2012 годом. Секунды могут быть опущены.
Автор облегчает задачу: в каждом месяце 30 дней.
Примеры:
4. Курсив в MarkDown
Задача:
Преобразовать текст, обрамленный в звездочки, в курсив. Не трогать текст в двойных звездочках (жирный).
Почитать подробнее про MarkDown можно в википедии.
Примеры:
5. Числа
Задача:
Выбрать числа с запятой или пробелом, в качестве разделителя разрядов. (к счастью обошлось без моммайе)
Примеры:
6. IPv4 адреса
Задача:
Выбрать IPv4 адреса во всех возможных, представлениях: десятичном, шестнадцатеричном и восьмеричном. С точками и без. Подробнее про IP адреса можно узнать в википедии
7. Доменные имена
Задача:
Доменные имена для протоколов http и https, с необязательным слешем в конце. Специальые символы не используются.
8. Повторяющиеся пункты в списке MarkDown
Задача:
Найти и выделить жирным (**) повтряющиеся пункты в MarkDown-списке.
Примеры:
* First list item
* Second list item
=>
* First list item
* Second list item
* Repeated list item
* Repeated list item
=>
* Repeated list item
* **Repeated list item**
9. Ссылки в MarkDown
Задача:
Преобразовать MarkDown ссылки в HTML. Выглядят вот так: [text](http://example.com)
Главное не перепутать с картинками: 
Примеры:
10. Делим предложение на токены.
Задача:
Разбить предложение на токены. Это может быть полезно, например, для поисковой системы.
Есть несколько правил:
- Несколько слов в кавычках должны попасть в один токен
This «huge test» is pointless => this,huge test,is,pointless
Suzie Smith-Hopper test—hyphens => Suzie,Smith-Hopper,test,hyphens.
11. Буквы в алфавитном порядке.
Задача:
Выбрать последовательность неповторяющихся символов в алфавитнои порядке.Пробелы нужно игнорировать. К сожалению известные мне решения не очень удачны.
Примеры:
12. Исправляем пробелы
Задача:
Убрать повторяющиеся пробелы и знаки табуляции, оставить по одному пробелу между словами и по два между предложениями.
Примеры:
13. Повторяющиеся слова друг под другом
Задача:
Выбрать повторяющиеся слова, которые находятся непосредственно друг под другом.
Предполагается использование моноширинного шрифта. Строки длиннее 32х символов переносятся.
Примеры:
This sentence is pretty long and
this sentence is also a test — Да
This sentence also shouldn’t
match as this has no words
below. — Нет
14. Брутфорсим химические элементы
Задача:
>Выбираем первые 50 химических элементов таблицы менделеева. Решение довольно очевидное, поэтому задача — найти максимально короткое решение.
15. Музыкальные аккорды
Задача:
Выбрать музыкальные аккорлы, например как Cmin, или Bmaj. Нужны и краткая и полная записи. Для данной задачи предпложим, что аккорды E♯, B♯, F♭ and C♭ не существует.
Так же обратите внимание, что диез (♯)
это не то же самое, что решетка (#).
Примеры:
16. Брутфорсим химические элементы
Задача:
Выбрать химические элементы с атомным числом больше 50.
Примеры:
17. Регулярное выражение для регулярного выражения.
Задача:
Выбрать правильно построенное регулярное выражение.Для начала ограничимся литералами (возможно экранированными), классами и несколькими квантификаторами.
Примеры:
18. IRC — Сообщения
Задача:
Выбрать правильно сформированное IRC сообщение.
Вот ссылка на русскую версию спецификаци.
Источник
JavaScript: изучаем регулярные выражения на практике

Регулярное выражение (далее также — регулярка) — это последовательность специальных символов, формирующих паттерн или шаблон (pattern), который сопоставляется со строкой.
Цель такого сопоставления может состоять либо в поиске подстроки в строке, например, для замены подстроки, либо в определении соответствия строки шаблону для валидации строки.
В данной статье мы сосредоточимся на валидации.
Что конкретно мы будем делать? Мы возьмем несколько регулярок из validator.js (наиболее популярной библиотеки для валидации данных с помощью регулярных выражений) и произведем их подробный разбор. Также мы рассмотрим несколько дополнительных регулярок и один алгоритм.
Как результат, мы реализуем несколько полезных функций, которые вы впоследствии сможете использовать в своих проектах.
Здесь можно получить общую информацию о регулярных выражениях, а здесь — более подробные сведения. Рекомендую ознакомиться с указанными материалами — так вам будет легче воспринимать дальнейшую информацию.
Еще парочка полезных ссылок:
Интерактивный редактор (песочница) для создания и тестирования регулярных выражений. Одной из особенностей данной песочницы является автоматически генерируемое объяснение регулярных выражений, что бывает очень полезным
Для того, чтобы немного размять мозги, начнем с двух «валидаторов», в которых регулярные выражения не используются.
Является ли строка пустой?
Метод trim() удаляет пробелы в начале и конце строки. Свойство length содержит количество символов, из которых состоит строка. Если строка не содержит символов, значит, ее свойство length имеет значение 0 . В этом случае выражение str.length === 0 возвращает true . В противном случае, возвращается false .
Данную функцию можно переписать так:
Является ли значение «логическим»?
Метод indexOf() возвращает индекс элемента или -1 при отсутствии элемента в массиве. Если элемент в массиве есть, его индекс будет равным 0 или больше (в пределах длины массива — 1). В этом случае выражение arr.indexOf(str) >= 0 возвращает true . Иначе, возвращается false .
Обратите внимание: в данном случае логическими считаются не только значения true и false , но также 1 (обозначающее истину) и 0 (обозначающее ложь). Также обратите внимание, что функция принимает только строку (как и функции, которые будут рассматриваться в дальнейшем), поэтому второй вызов функции isBoolean() с логическим значением false возвращает false .
Данную функцию можно переписать так:
Размялись? Отлично. Переходим к регуляркам.
Состоит ли строка только из букв?
- ^ и $ — символы начала и конца строки, соответственно (границы)
- [] — набор символов, перечисление (символ строки должен совпадать хотя бы с одним из вариантов)
- A-Z или А-ЯЁ — диапазон букв (например, А-ЯЁ — это все буквы киррилицы от А до Я + буква Ё , которая стоит особняком)
Обратите внимание: A-Z — это не тоже самое, что символьный класс \w . \w означает любая буква латиницы ИЛИ любая цифра ИЛИ символ нижнего подчеркивания.
- + — один или более предшествующий символ, т.е. символ, находящийся перед + (квантификатор)
- i — регистронезависимый поиск, т.е. поиск осуществляется без учета того, из больших или маленьких букв состоит строка (флаг)
Читаем регулярку: строка ДОЛЖНА состоять хотя бы из одной (одной или более) буквы, независимо от регистра.
Состоит ли строка только из букв и/или целых чисел?
Разбор: такие же спецсимволы, что и в предыдущем примере +
- 0-9 — диапазон цифр от 0 до 9 ; данный диапазон можно заменить символьным классом \d , означающим любое число, для латиницы получится /^[\dA-Z]+$/i
Обратите внимание: здесь мы также не можем использовать \w из-за нижнего подчеркивания. Впрочем, мы можем исключить его из проверки, написав что-то вроде /^[^\W_]$/i , где [^] означает любой символ, кроме указанных в наборе (одним из таких символов является _ ), \W — НЕ буква латиницы, НЕ число и НЕ нижнее подчеркивание. Таким образом, [^\W_] означает любой символ, который НЕ является нижним подчеркиванием, а также не относится к буквам латиницы ИЛИ цифрам. Или в переводе на человеческий язык — любой символ, который является буквой латиницы или числом.
Читаем регулярку: строка ДОЛЖНА состоять хотя бы из одной буквы И/ИЛИ (арабского — в дальнейшем предполагается) числа, без учета регистра
Является ли значение почтовым индексом?
Обратите внимание: в большинстве случаев при валидации предполагается, что строка прошла предварительную очистку от пробелов и других символов, которых в ней быть не должно (см. ниже).
Читаем: значение ДОЛЖНО состоять (точно — в дальнейшем предполагается) из 6 цифр.
Является ли значение номером паспорта?
- в самом регулярном выражении нет ничего нового — 10 цифр (или 2 цифры + 2 цифры + 6 цифр — в оригинале)
- removeSpaces() — утилита для удаления из строки пробелов, поскольку номер паспорта может выглядеть как 12 34 567890 , 1234 567890 и т.д.
- \s означает пробельный символ: пробел, табуляция, перенос строки и т.д. (символьный класс)
- g — глобальный поиск, т.е. будут обнаружены все пробелы, имеющиеся в строке, а не только первый (флаг)
Читаем: значение ДОЛЖНО состоять из 10 цифр.
Является ли значение числом (целым или с плавающей точкой/запятой)?
- numeric — функция, возвращающая регулярное выражение с указанным разделителем (delimiter), которым по умолчанию является символ . ; это один из тех немногих случаев, когда для создания регулярки используется объект RegExp , позволяющий создавать регулярное выражение динамически, в отличие от // , создающего статический шаблон
Обратите внимание: символ . необходимо экранировать с помощью \ или, в данном случае, с помощью \\ (чтобы не экранировать $ ). Экранирование превращает . в обычную точку, в противном случае, этот символ будет иметь специальное значение — любой символ. Мы также экранируем любой другой символ, переданный в функцию isNumeric() в качестве разделителя (побочный эффект), но это не страшно.
? — НОЛЬ или ОДИН предшествующий символ (квантификатор); по сути, применение этого квантификатора делает предшествующий символ опциональным (необязательным)
* — НОЛЬ или БОЛЕЕ предшествующих символов (квантификатор); этот квантификатор также делает предшествующий символ необязательным
(2*\.)? — необязательная группа, которая МОЖЕТ состоять из числа и точки ИЛИ только из точки (или другого разделителя)
9+ — хотя бы одна цифра
Читаем: значение ДОЛЖНО состоять хотя бы из одной цифры и МОЖЕТ включать знак + или — в начале строки, за которым МОЖЕТ следовать любое количество цифр и разделитель ИЛИ только разделитель
Является ли строка цветом в шестнадцатиричном формате?
- длина регулярки может испугать, но это всего лишь повторяющийся шаблон
- #? — необязательный символ #
- [0-9A-F]
— n любых чисел ИЛИ букв латиницы от A до F (без учета регистра) - | — альтерация, ИЛИ (строка должна совпадать с одним из вариантов — наборов)
Читаем: строка ДОЛЖНА состоять ЛИБО из 3, ЛИБО из 4, ЛИБО из 6, ЛИБО из 8 букв латиницы от A до F (без учета регистра) И/ИЛИ цифр и МОЖЕТ включать символ # в начале
Является ли строка цветом в формате RGB или RGBA ?
Является ли значение номером сотового телефона?
Функция (для России):
- \+? — опциональный символ + ; обратите внимание на экранирование
- (\+?7|8)? — опциональная группа, которая МОЖЕТ состоять из символа + и числа 7 или 8 ИЛИ только из числа 7 или 8
- removeNonDigits() — утилита для удаления всех символов, которые не являются числом ( \D )
Читаем: строка ДОЛЖНА состоять из 10 цифр, первым из которых ДОЛЖНО БЫТЬ число 9 , и МОЖЕТ включать символ + и число 7 или 8 ИЛИ только число 7 или 8 в начале
Перед тем, как переходить к самой сложной части, поиграем с редко используемыми, но от того не менее интересными возможностями регулярных выражений.
Еще парочка полезных утилит
Функция для удаления из строки ВСЕХ пробелов
Функция для форматирования даты
Теперь поговорим о строках, к содержанию которых предъявляются особые требования. Под такими строками я подразумеваю URL (или, если угодно, URI ) и email . В принципе, сюда же можно отнести пароли, требования к которым предъявляются не нормативными документами ( RFC ), а клиентами/заказчиками/разработчиками.
URL
URL (Uniform Resource Locator — унифицированный указатель ресурса) — система унифицированных адресов электронных ресурсов, или единообразный определитель местонахождения ресурса.
Он состоит из следующих частей:

Требования, предъявляемые к «урлам», содержатся, в основном, в RFC 3986 . Согласно этому документу URL может содержать следующие символы:
Однако, при этом не уточняется, в какой части URL какие символы могут использоваться.
Также в названном документе приводится регулярка для разбора урлов (приложение B ), которая выглядит так (числа — это номера групп):
Попробуем ее применить:
Данная регулярка отлично подходит для простых URL (как в приведенном примере), но в более сложных случаях лучше использовать конструктор URL() :
Вот один из возможных вариантов регулярки для проверки URL с учетом протокола http(s) , а также без учета некоторых символов:
Электронная почта — технология и служба по пересылке и получению электронных сообщений между пользователями компьютерной сети.
Адрес электронной почты ( email ) состоит из из следующих частей:
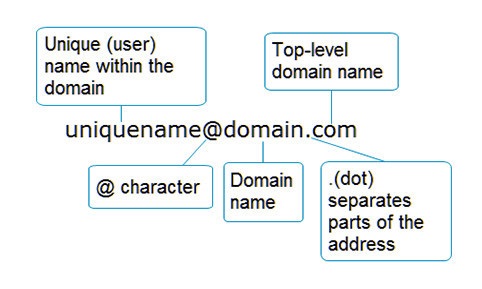
Что касается символов, которые могут использоваться в адресе электронной почты, то здесь ситуация довольно неоднозначная, поскольку существует большое количество RFC , по-разному регламентирующих этот вопрос. Относительно полный список этих RFC можно найти здесь.
В простейшем случае, регулярное выражение для определения того, является ли значение email , может выглядеть так:
Или можно обойтись вообще без регулярки:
Однако, любой символ — это как any в TypeScript — обуславливает ненадежность регулярного выражения. Но, с повышением точности регулярки, ее сложность растет в геометрической прогрессии.
Вот гораздо более продвинутый (надежный) пример:
Пароль
К паролю могут предъявляться самые разные требования. Как правило, среди таких требований значится следующее:
- определенная длина или диапазон пароля, т.е. ограничение минимального ИЛИ минимального и максимального количества символов
- минимум одна большая буква
- минимум одна маленькая буква
- минимум одна цифра
- минимум один спецсимвол
Эти требования можно комбинировать. Переведем их на язык регулярных выражений:
Не забывайте модифицировать [-\w#!$@%^&*+
=:;?\/] при добавлении/удалении групп.
Номер карты
Напоследок, рассмотрим один интересный алгоритм — алгоритм Луна, который используется для вычисления контрольной цифры номера пластиковой карты в соответствии со стандартом ISO/IEC 7812 с целью ее (номера) валидации.
В упрощенном виде этот алгорит включает следующие шаги:
- Цифры проверяемой последовательности нумеруются справа налево.
- Цифры, оказавшиеся на нечетных местах, остаются без изменений.
- Цифры, стоящие на четных местах, умножаются на 2.
Обратите внимание: речь идет не о «четности» числа, а о четности его позиции в строке.
- Если в результате такого умножения возникает число больше 9, оно заменяется суммой цифр получившегося произведения — однозначным числом, то есть цифрой.
- Все полученные в результате преобразования цифры складываются. Если сумма кратна 10, то исходные данные верны.
Реализация алгоритма из Википедии:
validator.js предлагает такой вариант рассматриваемого алгоритма:
Попробуем реализовать этот алгоритм в одну строку:
Как видите, регулярные выражения — тема, конечно, сложная, но довольно интересная и чрезвычайно полезная. Редкий проект обходится без необходимости очистки или валидации данных, вводимых пользователем и (в меньшей степени, но все же) «прилетающих» с сервера. Владение языком регулярных выражений существенно облегчает решение многих задач, возникающих в веб-разработке.
Обратите внимание: регулярные выражения предоставляют широкий простор для творчества, поэтому приведенные в статье паттерны можно реализовать совершенно по-разному, главный вопрос в том, решает ли регулярное выражение поставленную перед ней задачу и насколько хорошо она это делает, т.е. насколько регулярка является надежной и как сильно ее использование влияет на производительность (часто это влияние оказывается критичным даже в случае с простыми шаблонами).
Подборка функций для валидации, реализацией которых мы занимались на протяжении статьи:
Это все, о чем я хотел вам сегодня рассказать. Приветствуются любые замечания, дополнения и предложения.
Купить VPS-хостинг с быстрыми NVMе-дисками и посуточной оплатой у хостинга Маклауд.
Источник