- Создайте свою первую нейронную сеть на Python с помощью Keras шаг за шагом
- Обзор учебника
- 1. Загрузить данные
- 2. Определите модель
- 3. Скомпилируйте модель
- 4. Подходящая модель
- 5. Оценить модель
- 6. Свяжите все вместе
- 7. Бонус: делать прогнозы
- Резюме
- Связанные Учебники
- Туториал: создание нейросети для анализа настроений в комментариях c Keras
- Что такое Keras?
- Что такое анализ настроений (сентимент-анализ)?
- Датасет IMDb
- Импорт зависимостей и получение данных
- Изучение данных
- Подготовка данных
- Создание и обучение модели
- Итоги
Создайте свою первую нейронную сеть на Python с помощью Keras шаг за шагом
Дата публикации 2016-05-24
Keras — это мощная и простая в использовании библиотека Python для разработки и оценкиглубокое обучениемоделей.
Он объединяет эффективные библиотеки численных вычислений Theano и TensorFlow и позволяет определять и обучать модели нейронных сетей в несколько коротких строк кода.
В этой статье вы узнаете, как создать свою первую модель нейронной сети на Python с использованием Keras.
- Обновление февраль / 2017: Обновлен пример прогнозирования, так что округление работает в Python 2 и Python 3.
- Обновление март / 2017: Обновлен пример для Keras 2.0.2, TensorFlow 1.0.1 и Theano 0.9.0.
- Обновление март / 2018: Добавлена альтернативная ссылка для загрузки набора данных, так как кажется, что оригинал удален.

Обзор учебника
Не требуется много кода, но мы будем постепенно его перешагивать, чтобы вы знали, как создавать свои собственные модели в будущем.
Шаги, которые вы собираетесь охватить в этом руководстве, следующие:
- Загрузить данные.
- Определить модель.
- Скомпилировать модель.
- Подходящая модель.
- Оценить модель.
- Свяжите все это вместе.
Этот учебник имеет несколько требований:
- У вас установлен и настроен Python 2 или 3.
- У вас установлен и настроен SciPy (включая NumPy).
- У вас установлены и настроены Keras и серверная часть (Theano или TensorFlow).
Если вам нужна помощь в вашей среде, см. Учебник:
Создайте новый файл с именемkeras_first_network.pyи введите или скопируйте и вставьте код в файл, как вы идете.
1. Загрузить данные
Всякий раз, когда мы работаем с алгоритмами машинного обучения, которые используют стохастический процесс (например, случайные числа), хорошей идеей будет установить начальное число случайных чисел.
Это сделано для того, чтобы вы могли запускать один и тот же код снова и снова и получать один и тот же результат. Это полезно, если вам нужно продемонстрировать результат, сравнить алгоритмы с использованием одного и того же источника случайности или отладить часть вашего кода.
Вы можете инициализировать генератор случайных чисел любым начальным числом, например:
Теперь мы можем загрузить наши данные.
В этом уроке мы собираемся использовать набор данных о диабете у индейцев пима. Это стандартный набор данных для машинного обучения из репозитория UCI Machine Learning. В нем описываются данные медицинских карт пациентов индейцев пима и было ли у них начало диабета в течение пяти лет.
Таким образом, это проблема бинарной классификации (начало диабета 1 или не 0). Все входные переменные, которые описывают каждого пациента, являются числовыми. Это облегчает использование непосредственно с нейронными сетями, которые ожидают числовые входные и выходные значения, и идеально подходит для нашей первой нейронной сети в Керасе.
Загрузите набор данных и поместите его в локальный рабочий каталог, так же, как ваш файл python. Сохраните его с именем файла:
Теперь вы можете загрузить файл напрямую, используя функцию NumPyloadtxt (), Есть восемь входных переменных и одна выходная переменная (последний столбец). После загрузки мы можем разбить набор данных на входные переменные (X) и выходную переменную класса (Y).
Мы инициализировали наш генератор случайных чисел, чтобы обеспечить воспроизводимость наших результатов, и загрузили наши данные. Теперь мы готовы определить нашу модель нейронной сети.
Обратите внимание, что набор данных имеет 9 столбцов, а диапазон 0: 8 будет выбирать столбцы от 0 до 7, останавливаясь перед индексом 8. Если это плохо для вас, то вы можете узнать больше о нарезке массивов и диапазонах в этом посте:
2. Определите модель
Модели в Керасе определяются как последовательность слоев.
Мы создаем последовательную модель и добавляем слои по одному, пока не будем довольны нашей топологией сети.
Первое, что нужно сделать, это убедиться, что входной слой имеет правильное количество входов. Это можно указать при создании первого слоя сinput_dimаргумент и установка его в 8 для 8 входных переменных.
Как мы узнаем количество слоев и их типы?
Это очень сложный вопрос. Мы можем использовать эвристику, и часто лучшая структура сети определяется путем проб и экспериментов. Как правило, вам нужна сеть, достаточно большая, чтобы охватить структуру проблемы, если это вообще поможет.
В этом примере мы будем использовать полностью подключенную сетевую структуру с тремя уровнями.
Полностью связанные слои определяются с помощью класса Dense. Мы можем указать количество нейронов в слое в качестве первого аргумента, метод инициализации в качестве второго аргумента какв этоми укажите функцию активации, используяактивацияаргумент.
В этом случае мы инициализируем веса сети для небольшого случайного числа, сгенерированного из равномерного распределения (‘единообразный‘), В данном случае от 0 до 0,05, потому что это стандартная инициализация веса в Керасе по умолчанию Другой традиционной альтернативой будет ‘нормальный’для малых случайных чисел, сгенерированных из распределения Гаусса.
Мы будем использоватьвыпрямитель( «ReluActivation) функция активации на первых двух слоях и сигмовидная функция в выходном слое. Раньше было так, что функции активации сигмоида и танга были предпочтительными для всех слоев. В наши дни лучшая производительность достигается с помощью функции активации выпрямителя. Мы используем сигмоид на выходном слое, чтобы обеспечить выход нашей сети в диапазоне от 0 до 1 и легко сопоставить его с вероятностью класса 1 или привязать к жесткой классификации любого класса с пороговым значением по умолчанию, равным 0,5.
Мы можем собрать все вместе, добавив каждый слой. Первый слой имеет 12 нейронов и ожидает 8 входных переменных. Второй скрытый слой имеет 8 нейронов и, наконец, выходной слой имеет 1 нейрон, чтобы предсказать класс (начало диабета или нет).
3. Скомпилируйте модель
Теперь, когда модель определена, мы можем ее скомпилировать.
Компиляция модели использует эффективные числовые библиотеки под обложками (так называемый бэкэнд), такие как Theano или TensorFlow. Серверная часть автоматически выбирает лучший способ представления сети для обучения и прогнозирования работы на вашем оборудовании, таком как процессор или графический процессор, или даже распределенном.
При компиляции мы должны указать некоторые дополнительные свойства, необходимые при обучении сети. Помните, что тренировка сети означает поиск наилучшего набора весов для прогнозирования этой проблемы.
Мы должны указать функцию потерь, которая будет использоваться для оценки набора весов, оптимизатор, используемый для поиска по различным весам для сети, и любые дополнительные метрики, которые мы хотели бы собирать и сообщать во время обучения.
В этом случае мы будем использовать логарифмические потери, которые для задачи бинарной классификации определены в Керасе как «binary_crossentropy«. Мы также будем использовать эффективный алгоритм градиентного спуска »Адам«Ни по какой другой причине это эффективный дефолт. Узнайте больше об алгоритме оптимизации Адама в статье «Адам: метод стохастической оптимизации«.
Наконец, поскольку это проблема классификации, мы будем собирать и сообщать точность классификации как метрику.
4. Подходящая модель
Мы определили нашу модель и скомпилировали ее для эффективного вычисления.
Теперь пришло время выполнить модель на некоторых данных.
Мы можем обучить или приспособить нашу модель к нашим загруженным данным, позвонивпоместиться()функция на модели.
Процесс обучения будет проходить в течение фиксированного числа итераций по набору данных, называемому эпохами, который мы должны указать, используяnepochsаргумент. Мы также можем установить количество экземпляров, которые оцениваются перед выполнением обновления веса в сети, которое называется размером пакета и устанавливается с помощьюразмер партииаргумент.
Для этой проблемы мы будем выполнять небольшое количество итераций (150) и использовать сравнительно небольшой размер пакета, равный 10. Опять же, они могут быть выбраны экспериментально методом проб и ошибок.
Это где работа происходит на вашем процессоре или графическом процессоре.
В этом примере графическая карта не требуется, но если вы заинтересованы в том, как дешево запускать большие модели на аппаратном GPU в облаке, посмотрите этот пост:
5. Оценить модель
Мы обучили нашу нейронную сеть всему набору данных, и мы можем оценить производительность сети на том же наборе данных.
Это даст нам только представление о том, насколько хорошо мы смоделировали набор данных (например, точность поезда), но не о том, насколько хорошо алгоритм может работать с новыми данными. Мы сделали это для простоты, но в идеале вы могли бы разделить ваши данные на обучающие и тестовые наборы данных для обучения и оценки вашей модели.
Вы можете оценить свою модель на тренировочном наборе данных, используяоценки ()функционировать в вашей модели и передать ему те же входные и выходные данные, используемые для обучения модели.
Это создаст прогноз для каждой входной и выходной пары и соберет оценки, включая средние потери и любые настроенные вами показатели, например, точность.
6. Свяжите все вместе
Вы только что видели, как вы можете легко создать свою первую модель нейронной сети в Керасе.
Давайте свяжем все это в полный пример кода.
Запустив этот пример, вы должны увидеть сообщение для каждой из 150 эпох, печатающих потери и точность для каждого, с последующей окончательной оценкой обученной модели в наборе обучающих данных.
На моей рабочей станции, работающей на ЦП с бэкэндом Theano, требуется около 10 секунд.
Заметка: Если вы попытаетесь запустить этот пример в блокноте IPython или Jupyter, вы можете получить ошибку. Причина — выходные индикаторы выполнения во время тренировки. Вы можете легко отключить их, установивмногословные = 0в призыве кmodel.fit (),
Обратите внимание, навык вашей модели может отличаться
Нейронные сети — это стохастический алгоритм, означающий, что один и тот же алгоритм на одних и тех же данных может обучать другую модель с разными навыками. Это особенность, а не ошибка. Вы можете узнать больше об этом в посте:
Мы попытались исправить случайное начальное число, чтобы гарантировать, что мы с вами получим одинаковую модель и, следовательно, одинаковые результаты, но это не всегда работает на всех системах. Я пишу больше опроблема воспроизведения результатов с моделями Keras здесь,
7. Бонус: делать прогнозы
Вопрос номер один, который мне задают:
После того, как я обучу свою модель, как я могу использовать ее для прогнозирования новых данных?
Мы можем адаптировать приведенный выше пример и использовать его для генерации прогнозов для обучающего набора данных, делая вид, что это новый набор данных, которого мы не видели раньше.
Делать прогнозы так же просто, как звонитьmodel.predict (), Мы используем функцию активации сигмоида на выходном слое, поэтому прогнозы будут в диапазоне от 0 до 1. Мы можем легко преобразовать их в четкое двоичное предсказание для этой задачи классификации, округлив их.
Полный пример, который делает прогнозы для каждой записи в обучающих данных, приведен ниже.
Запуск этого измененного примера теперь печатает прогнозы для каждого входного шаблона. Мы могли бы использовать эти прогнозы непосредственно в нашем приложении, если это необходимо.
Если у вас есть дополнительные вопросы о прогнозировании с помощью обученных моделей, см. Этот пост:
Резюме
В этой статье вы узнали, как создать свою первую модель нейронной сети, используя мощную библиотеку Keras Python для глубокого обучения.
В частности, вы узнали пять основных шагов с помощью Keras для создания нейронной сети или модели глубокого обучения, шаг за шагом, в том числе:
- Как загрузить данные.
- Как определить нейронную сеть в Керасе.
- Как скомпилировать модель Keras, используя эффективный числовой бэкэнд.
- Как обучить модель на данных.
- Как оценить модель по данным.
У вас есть вопросы о Керасе или об этом уроке?
Задайте свой вопрос в комментариях, и я сделаю все возможное, чтобы ответить.
Связанные Учебники
Вы ищете дополнительные учебники по глубокому обучению с Python и Keras?
Источник
Туториал: создание нейросети для анализа настроений в комментариях c Keras

Keras — популярная библиотека глубокого обучения, которая внесла большой вклад в коммерциализацию глубокого обучения. Библиотека Keras проста в использовании и позволяет создавать нейронные сети с помощью лишь нескольких строк кода Python.
Из статьи вы узнаете, как с помощью Keras создать нейронную сеть, предсказывающую оценку продукта пользователями по их отзывам, классифицируя ее по двум категориям: положительная или отрицательная. Эта задача называется анализом настроений (сентимент-анализ), и мы решим ее с помощью сайта с кинорецензиями IMDb. Модель, которую мы построим, также может быть применена для решения других задач машинного обучения после незначительной модификации.
Обратите внимание, что мы не будем вдаваться в подробности Keras и глубокого обучения. Этот пост предназначен для того, чтобы предоставить схему нейронной сети в Keras и познакомить с ее реализацией.
Содержание:
- Что такое Keras?
- Что такое анализ настроений?
- Датасет IMDB
- Импорт зависимостей и получение данных
- Изучение данных
- Подготовка данных
- Создание и обучение модели
Что такое Keras?
Keras — это библиотека для Python с открытым исходным кодом, которая позволяет легко создавать нейронные сети. Библиотека совместима с TensorFlow, Microsoft Cognitive Toolkit, Theano и MXNet. Tensorflow и Theano являются наиболее часто используемыми численными платформами на Python для разработки алгоритмов глубокого обучения, но они довольно сложны в использовании.
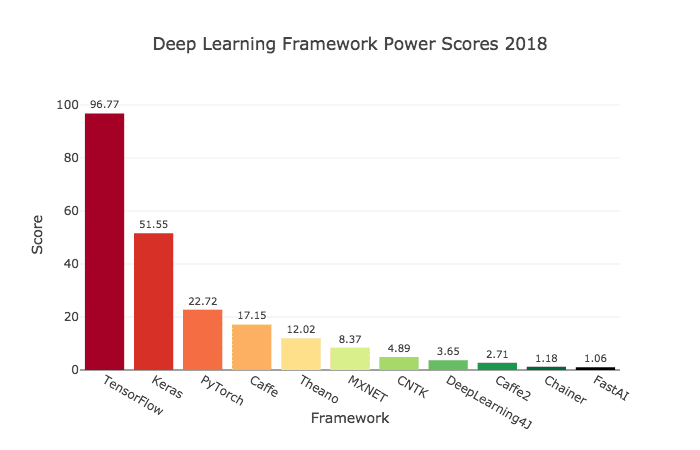 Оценка популярности фреймворков машинного обучения по 7 категориям
Оценка популярности фреймворков машинного обучения по 7 категориям
Keras, наоборот, предоставляет простой и удобный способ создания моделей глубокого обучения. Ее создатель, François Chollet, разработал ее для того, чтобы максимально ускорить и упростить процесс создания нейронных сетей. Он сосредоточил свое внимание на расширяемости, модульности, минимализме и поддержке Python. Keras можно использовать с GPU и CPU; она поддерживает как Python 2, так и Python 3. Keras компании Google внесла большой вклад в коммерциализацию глубокого обучения и искусственного интеллекта, поскольку она содержит cовременные алгоритмы глубокого обучения, которые ранее были не только недоступными, но и непригодными для использования.
Что такое анализ настроений (сентимент-анализ)?
С помощью анализа настроений можно определить отношение (например, настроение) человека к тексту, взаимодействию или событию. Поэтому сентимент-анализ относится к области обработки естественного языка, в которой смысл текста должен быть расшифрован для извлечения из него тональности и настроений.
 Пример шкалы анализа настроений
Пример шкалы анализа настроений
Спектр настроений обычно подразделяется на положительные, отрицательные и нейтральные категории. С использованием анализа настроений можно, например, прогнозировать мнение клиентов и их отношение к продукту на основе написанных ими обзоров. Поэтому анализ настроений широко применяется к обзорам, опросам, текстам и многому другому.
Датасет IMDb
Датасет IMDb состоит из 50 000 обзоров фильмов от пользователей, помеченных как положительные (1) и отрицательные (0).
- Рецензии предварительно обрабатываются, и каждая из них кодируется последовательностью индексов слов в виде целых чисел.
- Слова в обзорах индексируются по их общей частоте появления в датасете. Например, целое число «2» кодирует второе наиболее частое используемое слово.
- 50 000 обзоров разделены на два набора: 25 000 для обучения и 25 000 для тестирования.
Датасет был создан исследователями Стэнфордского университета и представлен в статье 2011 года, в котором достигнутая точность предсказаний была равна 88,89%. Датасет также использовался в рамках конкурса сообщества Keggle «Bag of Words Meets Bags of Popcorn» в 2011 году.
Импорт зависимостей и получение данных
Начнем с импорта необходимых зависимостей для предварительной обработки данных и построения модели.
Загрузим датесет IMDb, который уже встроен в Keras. Поскольку мы не хотим иметь данные обучения и тестирования в пропорции 50/50, мы сразу же объединим эти данные после загрузки для последующего разделения в пропорции 80/20:
Изучение данных
Изучим наш датасет:
Можно видеть, что все данные относятся к двум категориям: 0 или 1, что представляет собой настроение обзора. Весь датасет содержит 9998 уникальных слов, средний размер обзора составляет 234 слова со стандартным отклонением 173.
Рассмотрим простой способ обучения:
Здесь вы видите первый обзор из датасета, который помечен как положительный (1). Нижеследующий код производит обратное преобразование индексов в слова, чтобы мы могли их прочесть. В нем каждое неизвестное слово заменяется на «#». Это делается с помощью функции get_word_index ().
Подготовка данных
Пришло время подготовить данные. Нужно векторизовать каждый обзор и заполнить его нулями, чтобы вектор содержал ровно 10 000 чисел. Это означает, что каждый обзор, который короче 10 000 слов, мы заполняем нулями. Это делается потому, что самый большой обзор имеет почти такой же размер, а каждый элемент входных данных нашей нейронной сети должен иметь одинаковый размер. Также нужно выполнить преобразование переменных в тип float.
Разделим датасет на обучающий и тестировочный наборы. Обучающий набор будет состоять из 40 000 обзоров, тестировочный — из 10 000.
Создание и обучение модели
Теперь можно создать простую нейронную сеть. Начнем с определения типа модели, которую мы хотим создать. В Keras доступны два типа моделей: последовательные и с функциональным API.
Затем нужно добавить входные, скрытые и выходные слои. Для предотвращения переобучения будем использовать между ними исключение («dropout»). Обратите внимание, что вы всегда должны использовать коэффициент исключения в диапазоне от 20% до 50%. На каждом слое используется функция «dense» для полного соединения слоев друг с другом. В скрытых слоях будем используем функцию активации «relu», потому это практически всегда приводит к удовлетворительным результатам. Не бойтесь экспериментировать с другими функциями активации. На выходном слое используем сигмоидную функцию, которая выполняет перенормировку значений в диапазоне от 0 до 1. Обратите внимание, что мы устанавливаем размер входных элементов датасета равным 10 000, потому что наши обзоры имеют размер до 10 000 целых чисел. Входной слой принимает элементы с размером 10 000, а выдает — с размером 50.
Наконец, пусть Keras выведет краткое описание модели, которую мы только что создали.
Теперь нужно скомпилировать нашу модель, то есть, по существу, настроить ее для обучения. Будем использовать оптимизатор «adam». Оптимизатор — это алгоритм, который изменяет веса и смещения во время обучения. В качестве функции потерь используем бинарную кросс-энтропию (так как мы работаем с бинарной классификацией), в качестве метрики оценки — точность.
Теперь можно обучить нашу модель. Мы будем делать это с размером партии 500 и только двумя эпохами, поскольку я выяснил, что модель начинает переобучаться, если тренировать ее дольше. Размер партии определяет количество элементов, которые будут распространяться по сети, а эпоха — это один проход всех элементов датасета. Обычно больший размер партии приводит к более быстрому обучению, но не всегда — к быстрой сходимости. Меньший размер партии обучает медленнее, но может быстрее сходиться. Выбор того или иного варианта определенно зависит от типа решаемой задачи, и лучше попробовать каждый из них. Если вы новичок в этом вопросе, я бы посоветовал вам сначала использовать размер партии 32, что является своего рода стандартом.
Проведем оценку работы модели:
Отлично! Наша простая модель уже побила рекорд точности в статье 2011 года, упомянутой в начале поста. Смело экспериментируйте с параметрами сети и количеством слоев.
Полный код модели приведен ниже:
Итоги
Вы узнали, что такое анализ настроений и почему Keras является одной из наиболее популярных библиотек глубокого обучения.
Мы создали простую нейронную сеть с шестью слоями, которая может вычислять настроение авторов кинорецензий с точностью 89%. Теперь вы можете использовать эту модель для анализа бинарных настроений в других источниках, но для этого вам придется сделать их размер равным 10 000 или изменить параметры входного слоя.
Эту модель (с небольшими изменениями) можно применить и для решения других задач машинного обучения.
Источник