- Подготовка табличных данных для нейронных сетей
- Категориальные переменные
- Количественные переменные
- Представление категориальных переменных: однолинейные векторы
- Представление количественных переменных: важность нормализации(то есть, «Как прокормить вашу нейронную сеть»)
- Вменение, чтобы справиться с отсутствующими данными
- Резюме
- Обучающие наборы данных для нейронных сетей: как обучить и проверить нейросеть на Python
- Что такое обучающие данные?
- Оценка обучающих данных
- Создание набора обучающих данных
- Обучение нейросети
- Валидация нейросети
- Заключение
Подготовка табличных данных для нейронных сетей
Дата публикации Jun 1, 2019
Этот пост можно также назвать «всем, что я узнал в течение первого года обучения в докторантуре, работая с массивным электронным набором данных о состоянии здоровья». Здесь я рассмотрю разницу между категориальными и количественными переменными и объясню, как подготовить табличные данные для модели нейронной сети, в том числе:
- правильное представление категориальных переменных (от введения к горячим векторам)
- нормализация непрерывных переменных
- заполнение пропущенных значений (введение в вменение)
Лучше всего, широко применимый код предоставляется для выполнения всего вышеперечисленного наваштабличные данные! Вы можете скачать код для этого урока на GitHub:rachellea / glassboxmedicine / 2019-06-01-dataprocessing.py,
Категориальные переменные
категориальная переменнаяпеременная, которая принимает разные имена категорий Вот несколько примеров категориальных переменных:

Категориальные переменные подразделяются наноминальные и порядковые переменные:
- Номинальные переменныене имеют естественного порядка среди категорий. Приведенные выше примеры (фрукты, местонахождение и животное) являются «номинальными» переменными, потому что между категориями нет внутреннего порядка;
- Порядковые переменныеиметь естественный порядок. Например, буквенные оценки (A, B, C, D, F) или шкалы ранжирования (боль по шкале от 1 до 10) являются порядковыми переменными.
Номинальные категориальные переменные в медицине
Вот несколько примеров номинальных переменных (без естественного упорядочения) в наборах медицинских данных, а также некоторые примеры значений:
- Пол: женщина мужчина;
- раса: Индейцы индейцев или аляскинцев, азиаты, афроамериканцы или афроамериканцы, латиноамериканцы или латиноамериканцы, коренные гавайцы или другие жители тихоокеанских островов, белые;
- диагностика: сахарный диабет, гипертония, гиперлипидемия, рак легких, пневмония, инфаркт миокарда, волчанка, синдром раздраженного кишечника, инсульт;
- процедура: аппендэктомия, холецистэктомия, мастэктомия, АКШ *;
- лечение: ацетаминофен, алпразолам, амитриптилин, амлодипин, амоксициллин, аторвастатин;
- лабораторный тест:общий анализ крови (CBC), протромбиновое время (PT), базовая метаболическая панель (BMP), комплексная метаболическая панель (CMP), липидная панель, панель печени, гемоглобин A1c (HbA1c).
* Примечание: CABG расшифровывается как «шунтирование коронарной артерии», что является типом операции на открытом сердце. Врачи произносят эту аббревиатуру «капуста» (серьезно).

Порядковые категориальные переменные в медицине
Вот несколько примеров порядковых переменных (изначально упорядоченных) в наборах медицинских данных:
- Переменные ORDinal имеют ORDered;
- Номинальные переменные — это только NOMS (имена) без порядка.
Количественные переменные
количественныйпеременные имеют числовые значения, которые обычно представляют результат измерения. Существует два вида количественных переменных:
- дискретныйпеременные принимают исчисляемое количество значений. Примеры: количество рецептов, которые принимает пациент, количество заболеваний, с которыми пациент был диагностирован, количество операций, которые пациент перенес;
- непрерывныйпеременные принимают любое значение в пределах определенного диапазона значений. Примеры: рост, вес, индекс массы тела, диаметр опухоли, соотношение талии и бедер.
Дополнительное примечание по лабораторным тестам
Если ваша переменная является ИМЯ лабораторного теста, то это номинальная (категориальная) переменная, поскольку значения, которые она может принимать, являются разными именами различных лабораторных тестов, например, «Полный анализ крови», «Основная метаболическая панель», «Полная метаболическая панель».
Если ваша переменная является РЕЗУЛЬТАТОМ лабораторного теста, это может быть:
- Категориальный / Номинальный: например цвет ванализ мочи;
- Количественный / дискретный: например, подсчет количества лейкоцитов;
- Количественный / Непрерывный: например, уровень глюкозы в крови. Большинство результатов лабораторных тестов попадают в эту категорию, потому что они являются результатом измерения какого-либо вещества (в крови, спинномозговой жидкости, моче и т. Д.)
Представление категориальных переменных: однолинейные векторы
В машинном обучении категориальные переменные обычно представлены как «векторы с одним горячим током». Вектор с одним горячим током — это вектор, в котором все записи равны нулю, кроме одного, то есть только один элемент является «горячим» (ненулевым). Вот несколько горячих векторов:
Что хорошо в «горячих» векторах, так это то, что они позволяют вам представлять ваши категориальные переменные, не предполагая каких-либо особых отношений между ними.
Допустим, вы хотели представить категориальную переменную «животное», которая принимает значения собака, кошка и рыба
- Если вы сказали, что собака = 1, кошка = 2 и рыба = 3, это означает, что собака — это одна треть рыбы, а кошка — в два раза больше собаки, и все другие числовые отношения, которые не имеют смысла;
- Однако, если вы скажете, что собака = [1,0,0], кошка = [0,1,0] и рыба = [0,0,1], вы не сделали никаких предположений об отношениях между этими животными, потому что эти горячие векторы перпендикулярны:

Если у вас было 20 разных животных, которых вы хотели представить, это не проблема: просто используйте векторы с одной горячей длиной 20. Получившиеся 20 различных векторов с одной горячей точкой по-прежнему перпендикулярны друг другу в 20-мерном пространстве (которое, вы буду рад узнать, я будунепопытка набросать)
Как правило, длина нужного вам горячего вектора равна количеству различных возможных значений, которые может принимать ваша категориальная переменная. Если он может принимать 5 значений, вектор с одним горячим вектором должен быть длиной 5. Если он может принимать 1298 значений, длина вашего вектора с одним горячим током должна быть 1,298.
Что если в моем наборе данных будет много категориальных переменных?
Просто создайте разный горячий вектор для каждой категориальной переменной. Допустим, вы приняли участие в опросе и спросили у 3 человек их любимое животное, местоположение и фрукты. В конце концов, ваш набор данных ответов на опрос включает категориальные переменные «животное» (3 возможных значения), «местоположение» (4 возможных значения) и «фрукты» (2 возможных значения). Таким образом, вы должны:
- представлять «животное» с использованием горячего вектора длиной 3;
- представлять «местоположение» в виде отдельного горячего вектора длины 4;
- представлять «фрукт» как еще один горячий вектор длины 2.

Что если моя категориальная переменная может принимать несколько значений одновременно?
Что если в предыдущем опросе вы дали людям возможность выбрать несколько животных, мест или фруктов? Вы можете использовать «вектор с разогревом», который точно такой же, как вектор с разогревом, за исключением того, что несколько записей могут быть равны 1. Вот пример (изменен из предыдущего примера; дополнительные записи выделены желтым цветом) :

Категориальные переменные, которые могут принимать более одного значения, обычно встречаются в медицине. Например, диагнозы, процедуры и лекарства, извлеченные из медицинской карты пациента за десять лет, могут иметь более одного значения. У многих пациентов будет несколько прошлых диагнозов, несколько прошлых процедур и несколько прошлых лекарств. Таким образом, вам потребуется мульти-горячий вектор для диагностики, другой мульти-горячий вектор для процедур и другой мульти-горячий вектор для лекарств.
Вот фрагментпредоставленный кодкоторый преобразует каждую категориальную переменную в вектор с одним или несколькими значениями, в зависимости от ситуации, используяфункция панд get_dummies ():
Представление количественных переменных: важность нормализации(то есть, «Как прокормить вашу нейронную сеть»)
Теперь мы собираемся переключить передачи и поговорить о представлении количественных переменных. Кажется, что вы могли бы просто бросить эти переменные прямо в модель без дополнительной работы, потому что они уже числа. Однако, если вы строите модель нейронной сети, вы не хотите вводить необработанные количественные переменные, потому что они, вероятно, будут иметь очень разные масштабы, и если дать нейронным сетям номера разных масштабов, это будет печально (т.е. это будет нейронной сети труднее чему-либо научиться.)
Под «разными шкалами» я подразумеваю, что некоторые переменные могут принимать небольшие значения (например, диаметр опухоли = 0,5 см), а другие переменные могут принимать большие значения (например, вес = 350 фунтов). Нейронная сеть будет тренироваться более эффективно, если вы кормите его только маленькими, нормализованными значениями.
Вот обычная процедура нормализации количественной переменной перед тренировкой нейронной сети:
- Разделите ваши данные на обучающие, проверочные и тестовые наборы;
- Рассчитайте среднее значение вашей количественной переменной в тренировочном наборе;
- Рассчитайте стандартное отклонение вашей количественной переменной в тренировочном наборе;
- Нормализуйте каждое исходное значение вашей количественной переменной по ВСЕМ вашим данным (поезд, проверка и тест), используя среднее значение и стандартное отклонение, которое вы только что рассчитали на тренировочном наборе:

Вы должны сделать это отдельно для каждой количественной переменной в вашем наборе данных (например, отдельно для «диаметра опухоли» и «веса»), потому что у каждой количественной переменной будет другое среднее значение и другое стандартное отклонение.
Результатом выполнения вышеуказанных шагов является то, что все ваши количественные переменные теперь будут представлены в виде небольших чисел с центром в 0, что сделает их хорошей пищей для вашей нейронной сети.
Почему мы рассчитываем среднее и стандартное отклонение, используя ТОЛЬКО тренировочный набор? Почему бы не использовать весь набор данных? Ответ: Если бы мы включили тестовый набор в наши расчеты среднего и стандартного отклонения, мы бы просочились в информацию о тестовом наборе в наши тренировочные данные, что является обманом.
Вот фрагментпредоставленный кодкоторый нормализует непрерывные переменные, используяStandardScalerиз scikit-learn:
Вменение, чтобы справиться с отсутствующими данными
Часто значения данных отсутствуют. Возможно, участник опроса не ответил на все вопросы, или пациент получал лечение в другом состоянии, и его диагнозы, процедуры и лекарства не были включены в местную медицинскую карту.
Если мы читаем в файле данных с пропущенными значениями, эти значения будут «NaNs» или «не число». Мы должны заменить их на число, чтобы тренироваться. Заполнение пропущенных значений называется «вменением».
Существуют разные стратегии вменения. Вот одна разумная стратегия:
- Замените все пропущенные значения для категориальной переменной режимом обучения. Таким образом, если режим (наиболее часто выбираемое значение) для животного — «собака», мы заменяем все недостающие ответы на «Какое ваше любимое животное?» На «собака»;
- Замените все пропущенные значения для непрерывной переменной медианой тренировочного набора. Таким образом, если средняя высота составляет 5,2 фута, мы заменяем все отсутствующие записи для «высоты» на 5,2.
Вот фрагментпредоставленный кодкоторый выполняет вменение отсутствующих значений, используяфункция панд fillna ():
Резюме
- Тщательная подготовка данных имеет решающее значение для вашей нейронной сети для достижения хорошей производительности;
- Горячие векторы позволяют вводить категориальные переменные, не предполагая каких-либо конкретных числовых отношений между различными категориями;
- Нормализация ваших количественных переменных до небольших чисел с центром в нуле поможет вашей нейронной сети тренироваться более эффективно;
- Реальные наборы данных часто являются неполными. Ввод пропущенных значений с использованием медианы или режима соответствующей переменной позволит вам в любом случае построить модели на этих наборах данных.
О избранном изображении

Показанное изображениеСамоедская собакаЭто мой самый любимый вид собак. Эта собака появилась в камео в таблице «пример категориальных переменных».Забавные факты о самоедах:
- Самоеды разводились кочевыми оленеводами в Сибири;
- Самоеды являются одной из самых старых пород собак;
- Сарай из шерсти самоеда можно использовать для вязания одежды;
- Из-за их толстых пальто Самоеды могут оставаться хорошими и теплыми при температурах значительно ниже нуля.
Источник
Обучающие наборы данных для нейронных сетей: как обучить и проверить нейросеть на Python
В данной статье мы будем использовать для обучения многослойного перцептрона сгенерированные в Excel выборки, а затем посмотрим, как нейросеть работает с проверочными выборками.
Если вы хотите разработать нейронную сеть на Python, вы находитесь в правильном месте. Прежде чем углубиться в обсуждение о том, как использовать Excel для создания обучающих данных для вашей нейросети, для получения дополнительной информации посмотрите остальные статьи серии выше, в меню с содержанием.
Что такое обучающие данные?
В реальной жизни обучающие выборки состоят из данных измерений в сочетании с «решениями», которые помогут нейронной сети обобщить всю эту информацию в соответствующую связь вход-выход.
Например, предположим, что вы хотите, чтобы ваша нейронная сеть предсказывала вкусовые качества помидора на основе цвета, формы и плотности. Вы не представляете, как именно цвет, форма и плотность связаны с вкусностью, но вы можете измерить цвет, форму и плотность, и у вас есть вкусовые рецепторы. Таким образом, всё, что вам нужно сделать, это собрать тысячи и тысячи помидоров, записать их физические характеристики, попробовать каждый (лучшая часть), а затем поместить всю эту информацию в таблицу.
Каждая строка – это то, что я называю одной обучающей выборкой, и в ней четыре столбца: три из них (цвет, форма и плотность) являются столбцами входных данных, а четвертый – целевым выходным значением.
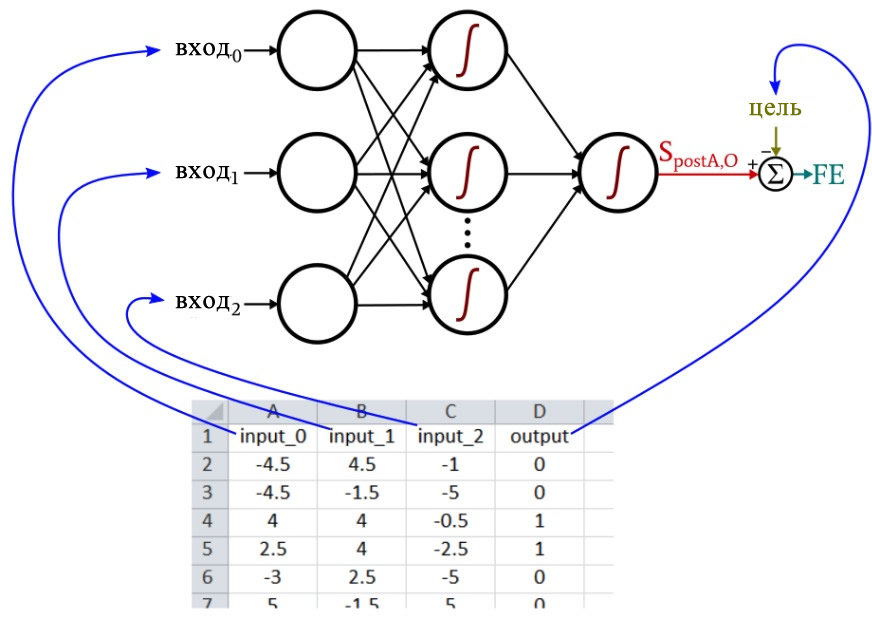 Рисунок 1 – Связь между данными в Excel и параметрами нейросети
Рисунок 1 – Связь между данными в Excel и параметрами нейросети
Во время обучения нейронная сеть найдет связь (если когерентная связь существует) между тремя входными значениями и выходным значением.
Оценка обучающих данных
Имейте в виду, что всё должно обрабатываться в числовом виде. Вы не можете в качестве входного параметра вашей нейронной сети использовать строку «сливовидная форма», а «аппетитный» не будет работать в качестве выходного значения. Вы должны количественно оценить ваши измерения и ваши классификации.
Для формы вы можете присвоить каждому помидору значение от –1 до +1, где –1 представляет собой идеальную сферу, а +1 означает крайне вытянутую форму. Что касается вкусовых качеств, вы можете оценивать каждый помидор по пятибалльной шкале от «несъедобного» до «восхитительного», а затем использовать унитарный код для сопоставления этих оценок с выходным вектором из пяти элементов.
Следующая диаграмма показывает, как этот тип кодирования используется для классификации выходных значений нейронной сети.
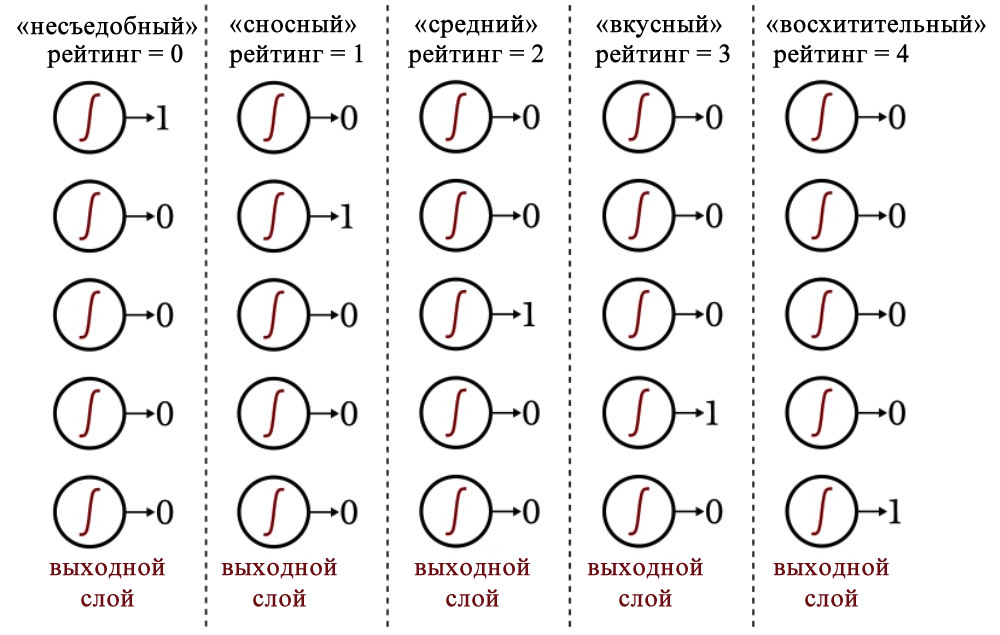 Рисунок 2 – Унитарный код для выходных значений нейросети
Рисунок 2 – Унитарный код для выходных значений нейросети
Выходная схема, использующая унитарный код, позволяет нам определить недвоичные классификации таким образом, чтобы это было совместимо с логистической сигмоидной функцией активации. Выходные данные логистической функции являются, по сути, двоичными, поскольку область перехода на графике является узкой по сравнению с бесконечным диапазоном входных значений, для которых выходное значение очень близко к минимальному или максимальному значению:
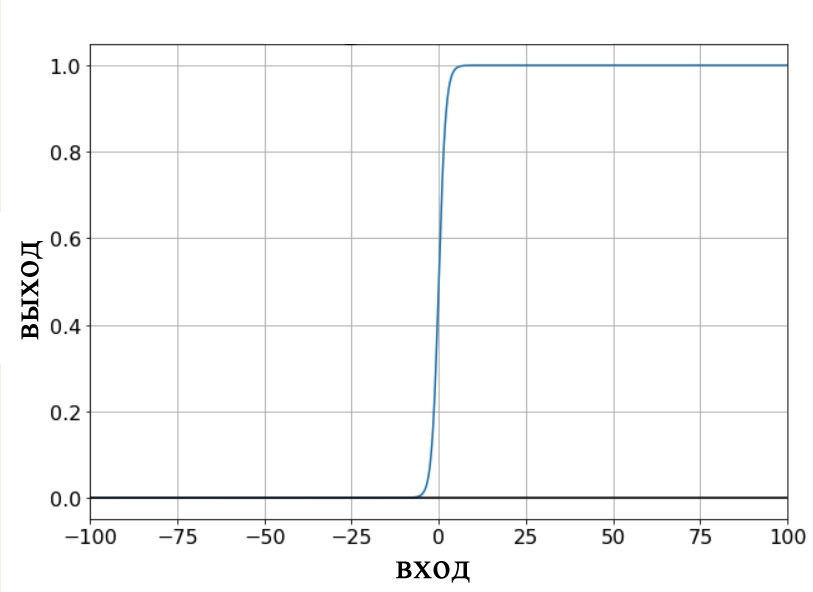 Рисунок 3 – График логистической функции
Рисунок 3 – График логистической функции
Таким образом, мы не хотим создавать эту нейросеть с одним выходным узлом, а затем предоставлять обучающие выборки, которые имеют выходные значения 0, 1, 2, 3 или 4 (или, если вы хотите оставаться в диапазоне от 0 до 1, это будут 0, 0,2, 0,4, 0,6 или 0,8), поскольку логистическая функция активации выходного узла будет устойчиво придерживаться минимального и максимального выходных значений.
Нейронная сеть просто не понимает, насколько нелепым было бы сделать вывод, что все помидоры либо несъедобны, либо восхитительны.
Создание набора обучающих данных
Нейронная сеть на Python, о которой мы говорили в части 12, импортирует обучающие выборки из файла Excel. Обучающие данные, которые я буду использовать для этого примера, организованы следующим образом:
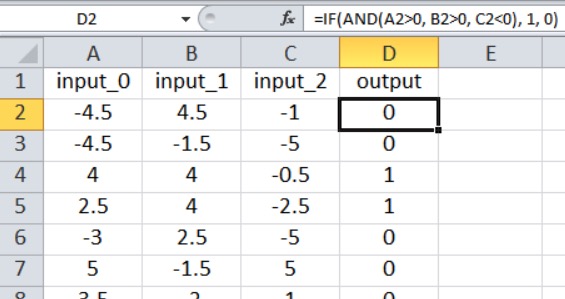 Рисунок 4 – Обучающие данные в таблице Excel
Рисунок 4 – Обучающие данные в таблице Excel
Наш текущий код для перцептрона ограничен одним выходным узлом, поэтому всё, что мы можем сделать, – это выполнить классификацию типа «истина/ложь». Входные значения – это случайные числа от –5 до +5, сгенерированные по формуле Excel:
Как показано на скриншоте, результат рассчитывается следующим образом:
Таким образом, выходное значение равно true , только если input_0 больше нуля, input_1 больше нуля, а input_2 меньше нуля. В противном случае выходное значение равно false .
Это математическая связь вход-выход, которую перцептрон должен извлечь из обучающих данных. Вы можете создать столько выборок, сколько захотите. Для такой простой задачи, как эта, вы можете достичь очень высокой точности классификации с 5000 выборками и одной эпохой.
Обучение нейросети
Вам нужно установить входную размерность на три ( I_dim = 3, если вы используете мои имена переменных). Я настроил нейросеть так, чтобы в ней было четыре скрытых узла ( H_dim = 4), и выбрал скорость обучения 0,1 ( LR = 0,1).
Найдите инструкцию training_data = pandas.read_excel(. ) и введите название своей таблицы (если у вас нет доступа к Excel, библиотека Pandas также может читать файлы ODS). Затем просто нажмите кнопку «Run». Обучение с 5000 выборками занимает всего несколько секунд на моем ноутбуке.
Если вы используете полную программу « MLP_v1.py », которую я включил в часть 12, валидация(смотрите следующий раздел) начинается сразу после завершения обучения, поэтому перед тем, как приступить к обучению нейросети, вам необходимо подготовить данные валидации.
Валидация нейросети
Чтобы проверить эффективность нейросети, я создаю вторую электронную таблицу и генерирую входные и выходные значения, используя точно такие же формулы, а затем импортирую эти проверочные данные так же, как импортировал обучающие данные:
В следующем фрагменте кода показано, как выполнить базовую валидацию:
Я использую стандартную процедуру прямого распространения для вычисления сигнала постактивации выходного узла, а затем использую оператор if / else для применения порогового значения, который преобразует значение постактивации в классификационное значение true / false .
Точность классификации вычисляется путем сравнения значения классификации с целевым значением для текущей выборки валидации, подсчета количества правильных классификаций и деления на количество выборок валидации.
Помните, что если вы закомментировали инструкцию np.random.seed(1) , при каждом запуске программы веса будут инициализироваться различными случайными значениями, и, следовательно, точность классификации будет меняться от одного запуска к следующему. Я выполнил 15 отдельных запусков с параметрами, указанными выше, 5000 обучающих выборок и 1000 проверочных выборок.
Самая низкая точность классификации составила 88,5%, самая высокая – 98,1%, а средняя – 94,4%.
Заключение
Мы рассмотрели важную теоретическую информацию, относящуюся к обучающим данным нейронной сети, и провели первый эксперимент по обучению и валидации нашего многослойного перцептрона на языке Python. Я надеюсь, вам интересна эта серия статей о нейронных сетях – мы добились большого прогресса со времени первой статьи, и есть еще много, что нам нужно обсудить!
Источник